요즘 물류 컨퍼런스에 가면 AI 얘기가 빠지지 않아요.
AI 배차 최적화, AI 운임 예측, AI 수요 예측 슬라이드마다 AI가 들어가 있어요. 물류의 미래는 AI라는 말을 어디서든 들어요. 실제로 맞는 말이에요.
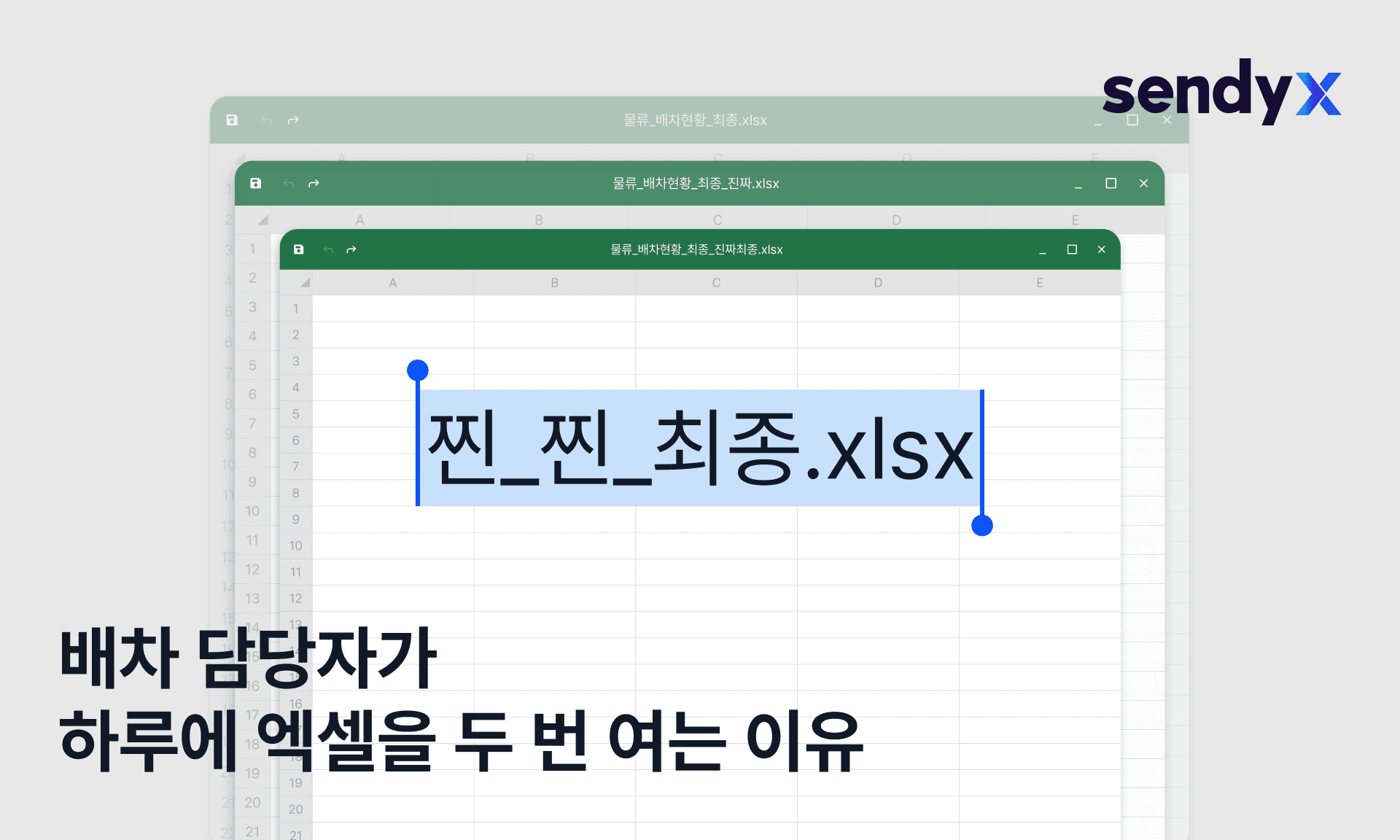
그런데 현장 담당자들은 오늘도 엑셀을 열어요.
1. AI가 작동하려면 뭐가 필요할까요
AI는 데이터로 작동해요.
정확하고, 일관되고, 연결된 데이터가 있어야 해요. AI가 배차를 최적화하려면 어떤 기사가 어떤 노선에서 얼마나 걸렸는지, 어떤 차종이 어떤 화물에 맞는지, 운임이 어떻게 형성되는지를 알아야 해요.
그런데 지금 많은 운송사의 데이터는 이렇게 생겼어요.
배차 내역은 담당자 개인 엑셀에 있어요. 운임 협의는 카톡에 있어요. 완료 증빙은 기사가 보낸 사진에 있어요. 정산 내역은 TMS에 있는데, 실제 운송과 맞지 않는 경우도 있어요.
흩어져 있고, 단절돼 있어요. 이 상태에서 AI를 얹으면 어떻게 될까요?
2. 연결되지 않은 데이터에 AI 한 스푼
정제되지 않은 데이터가 들어가면 정확한 결과가 안 나와요. 아무리 좋은 AI 모델도 입력 데이터가 부정확하면 엉터리 결과를 내요. 배차 데이터가 실시간으로 업데이트되지 않으면 AI가 보는 현황과 실제 현황이 달라요. 정산 데이터가 계산서 발행 여부에 따라 들쑥날쑥하면 수익률 예측이 틀려요.
실제로 AI를 도입했는데 "현장에서 안 맞아요"라는 이야기가 나오는 이유가 여기 있어요. AI 문제가 아니에요. 데이터 연결 문제예요.
GPS 내비게이션이 아무리 좋아도 지도 데이터가 틀리면 엉뚱한 곳으로 안내해요. AI도 마찬가지예요. 기반이 되는 데이터가 연결되지 않으면, AI는 좋은 도구가 아니라 자신감 있게 틀리는 도구가 돼요.
3. 센디가 AI를 먼저 경험한 방식
센디는 이미 AI를 쓰고 있어요. 수백만 건의 운송 데이터를 기반으로 AI 운임 최적화를 센디 플랫폼에 적용했어요. 노선, 차종, 시간대, 화물 유형에 따라 적정 운임을 제안해요. 실제로 작동해요.
왜 작동할까요. 센디는 화주와 기사를 직접 연결하는 정보망이에요. 매칭이 일어나는 순간부터 데이터가 하나의 시스템 안에서 만들어져요. 운임, 거리, 차종, 완료 여부. 이 데이터가 끊기지 않고 쌓여요. AI가 학습할 데이터가 일관되게 존재하는 거예요.
연결된 데이터가 있었기 때문에 AI가 작동한 거예요. 순서가 있었어요.
4. sendyX의 로드맵
sendyX는 AI 이야기를 하기 전에 연결 이야기를 먼저 해요.
이유는 하나예요. 지금 운송사 현장에서 가장 급한 문제는 AI가 없어서가 아니거든요. 시스템들이 연결되지 않아서예요.
정보망에서 배차된 데이터가 TMS로 자동으로 넘어오지 않아요. 운송이 완료돼도 정산 데이터와 이어지지 않아요. 기사별, 팀별, 화주별 데이터가 한 곳에 모이지 않아요.
이 상태에서 AI를 도입하면 좋은 AI가 나올 수 없어요. sendyX의 순서는 이렇게 돼요.
1단계: 연결
- 정보망, TMS, 정산을 하나로 잇는다. 데이터가 사람 손을 거치지 않고 흐르게 만든다.
2단계: 자동화
- 연결된 데이터 위에서 반복 작업을 자동화한다. 계산서 발행, 정산 요청, 완료 알림.
3단계: AI 최적화
- 쌓인 데이터로 패턴을 발견한다. 운임 최적화, 배차 제안, 수익률 예측.
5. 연결이 먼저인 이유
담당자가 매일 엑셀을 두 번 여는 건 AI가 없어서가 아니에요. 정보망에서 발생한 데이터가 TMS로 자동으로 안 넘어가서예요. 수익률이 왜곡되는 건 분석 도구가 없어서가 아니에요. 계산서 발행 여부에 따라 매입 데이터가 들쑥날쑥하기 때문이에요.
배차 담당자가 퇴사하면 운영이 흔들리는 건 시스템이 약해서가 아니에요. 지식이 시스템이 아닌 사람 안에 있어서예요. 이 문제들은 AI로 해결하는 게 아니에요. 연결로 해결해요.
연결이 되면 자동화가 가능해지고, 자동화가 되면 데이터가 쌓이고, 데이터가 쌓이면 그때 AI가 실제로 쓸모 있어져요.
sendyX가 AI보다 연결을 먼저 얘기하는 건, AI가 중요하지 않아서가 아니에요. AI가 작동하려면 연결이 먼저여야 하기 때문이에요.
sendyX가 만들어가는 방향이 궁금하다면, 아래에서 업데이트를 받아보세요.